
Life's a garden. Dig it.
Challenge¶
By hand, implement a multilayer perceptron that classifies stairs like these 👇

Assume the pixel values range between 0 (black) and 1 (white).
Data
Hint 1
Hint 2
Hint 3
Solution¶
There are multiple ways to do this. Here's one of them.
-
Design a perceptron that classifies "left stairs" .
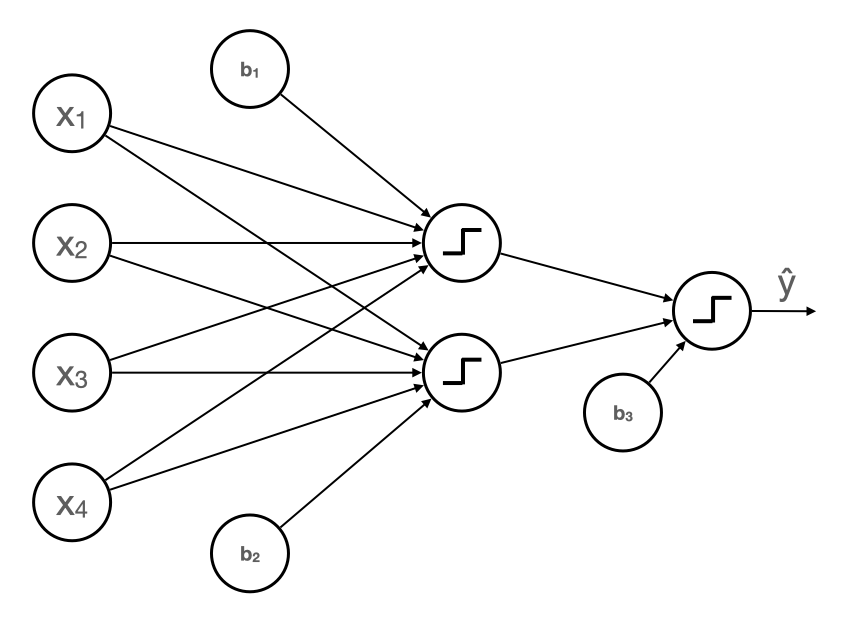
We know the model needs four inputs and a bias, so off-the-bat we can set up something like this.
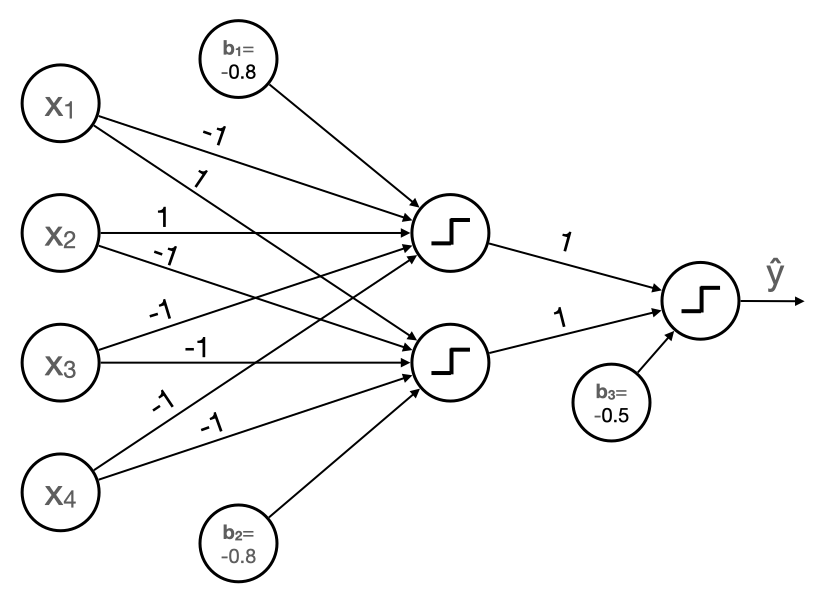
b ---------\ \ w1 \ x1 -----------\ \ \ \ w2 -------- x2 ---------- | _|¯ | -------- w3 / / x3 ----------/ / / w4 / x4 ---------- /Left stairs should have a dark x 1 x_1 x1, x 3 x_3 x3, and x 4 x_4 x4, and a light x 2 x_2 x2. So it makes sense to assign negative and positive weights respectively. For simplicity, we choose the following
b ---------\ \ w1 = -1 \ x1 -----------\ \ \ \ w2 = 1 -------- x2 ---------- | _|¯ | -------- w3 = -1 / / x3 ----------/ / / w4 = -1 / x4 ---------- /Now we must choose the bias. In a perfect left stairs image, x 1 x_1 x1, x 3 x_3 x3, and x 4 x_4 x4 will be 0, and x 2 x_2 x2 will be 1, so the weighted sum will be 1. As the image becomes less perfect, the weighted sum decreases. b = − 0.8 b = -0.8 b=−0.8 seems like a reasonable choice as it forces the weighted sum to be close to 1, but allows for a bit of noise.
b = -0.8 --\ \ w1 = -1 \ x1 -----------\ \ \ \ w2 = 1 -------- x2 ---------- | _|¯ | -------- w3 = -1 / / x3 ----------/ / / w4 = -1 / x4 ---------- / -
Design a perceptron that classifies "right stairs" .
Following the same process, we can quickly develop a perceptron like this one.
b = -0.8 --\ \ w1 = 1 \ x1 -----------\ \ \ \ w2 = -1 -------- x2 ---------- | _|¯ | -------- w3 = -1 / / x3 ----------/ / / w4 = -1 / x4 ---------- / -
At this point we have a model that classifies left stairs and another that classifies right stairs. Let's feed them into a downstream perceptron
b1 ---\ b3 ---\ x1 < ------ \ | P1 | -------\ \ x2 < ------ w1 ------- | _|¯ | ---> x3 < ------ ------- | P2 | -------/ x4 < ------ w2 b2 ---/Each Perceptron (P1 and P2 above) outputs a 0 or a 1. If either model outputs a 1, we want the final model to classify stairs. In other words, we want their sum to be greater than or equal to 1. We can achieve this by setting both weights to 1 and the bias term to -0.5. In other words, this 👇
b = -0.5 --\ \ P1 -----------\ \ w = 1 -------- | _|¯ | ---> -------- P2 ----------/ w = 1Notice how this perceptron mimmics an or operator.
Our final model looks like this
Food for thought
This example highlights how a multilayer perceptron can emulate conditional logic. This makes it a powerful prediction model.
Once you're convinced that MLP can be a good predictor, the question becomes How do we scale it?
Imagine connecting thousands of perceptrons across dozens of layers. Given some training dataset, how could we possibly find the optimal set of weights and biases?